
Adaptive Execution-Aware Bug Detection with Semantic Attention: ASABD Framework Using Large Language Models
DOI:
https://doi.org/10.26438/ijcse/v13i11.112Keywords:
Bug Detection, Large Language Models, Execution Aware Debugging, Adaptive Learning, Deep LearningAbstract
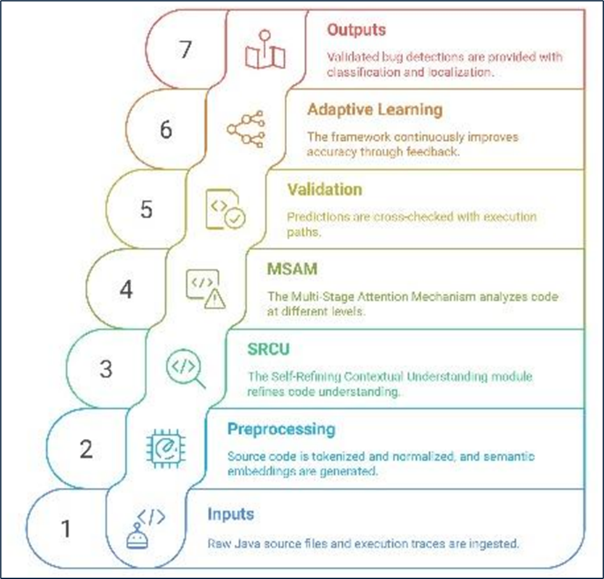
Traditional bug detection tools rely heavily on static code patterns, lacking execution-aware reasoning, adaptive learning, and semantic-level understanding, which results in high false positive rates and poor generalization across modern, large scale codebases. To address these limitations, we introduce the Adaptive Semantic-Aware Bug Detection (ASABD) framework, which uses Large Language Models (LLMs) for context-aware, execution-informed bug detection. ASABD introduces two core innovations: (1) the Self-Refining Contextual Understanding (SRCU) module, which iteratively improves predictions using execution trace feedback, enabling dynamic adaptation to different codebases (adaptive debugging), and (2) the Multi-Stage Attention Mechanism (MSAM), which captures structural, logical, and security-level dependencies in code for precise classification. These modules are motivated by the need to bridge static code analysis with runtime behavior and to improve semantic level bug understanding. Evaluated on the Defects4J dataset, ASABD achieves 94.7% precision, 91.3% recall, 92.9% F1-score, and 96.2% localization accuracy. It outperforms SonarQube, FindBugs, Random Forest, and DeepCode while reducing false positives by 57.2%. This work shows how execution-aware LLM reasoning can enhance bug detection across diverse software environments.
References
[1] S. A. Alsaedi, A. Y. Noaman, A. A. Gad-Elrab, F. E. Eassa, and S. Haridi, “Leveraging large language models for automated bug fixing,” Int. J. Adv. Comput. Sci. Appl., Vol.15, No.12, 2024.
[2] C. Gao, X. Hu, S. Gao, X. Xia, and Z. Jin, “The current challenges of software engineering in the era of large language models,” ACM Trans. Softw. Eng. Methodol., 2024.
[3] X. Hou et al., “Large language models for software engineering: A systematic literature review,” ACM Trans. Softw. Eng. Methodol., Vol.33, No.8, pp.1–79, 2024.
[4] S. Kang, J. Yoon, N. Askarbekkyzy, and S. Yoo, “Evaluating diverse large language models for automatic and general bug reproduction,” IEEE Trans. Softw. Eng., 2024.
[5] Y. Li, P. Liu, H. Wang, J. Chu, and W. E. Wong, “Evaluating large language models for software testing,” Comput. Stand. Interfaces, Vol.93, pp.103942, 2025.
[6] M. R. Lyu, B. Ray, A. Roychoudhury, S. H. Tan, and P. Thongtanunam, “Automatic programming: Large language models and beyond,” ACM Trans. Softw. Eng. Methodol., 2024.
[7] C. Wen et al., “Automatically inspecting thousands of static bug warnings with large language models: How far are we?” ACM Trans. Knowl. Discov. Data, Vol.18, No.7, pp.1–34, 2024.
[8] E. H. Y?lmaz, Automated Priority Detection in Software Bugs, Master’s thesis, Middle East Technical Univ., 2024.
[9] Z. Zheng et al., “Towards an understanding of large language models in software engineering tasks,” Empir. Softw. Eng., Vol.30, No.2, pp.50, 2025.
[10] A. A. Abbassi, L. D. Silva, A. Nikanjam, and F. Khomh, “Unveiling inefficiencies in LLM-generated code: Toward a comprehensive taxonomy,” arXiv preprint, 2025.
[11] F. Madeiral, S. Urli, M. Maia, and M. Monperrus, “BEARS: An extensible Java bug benchmark for automatic program repair studies,” in Proc. IEEE Int. Conf. Softw. Anal., EVol.Reeng. (SANER), pp.468–478, 2019.
[12] R. Just, D. Jalali, and M. D. Ernst, “Defects4J: A database of existing faults for Java programs,” in Proc. Int. Symp. Softw. Test. Anal. (ISSTA), ACM, 2014.
[13] S. Kang, J. Yoon, N. Askarbekkyzy, and S. Yoo, “Evaluating diverse large language models for automatic and general bug reproduction,” arXiv preprint, 2023.
[14] N. Ayewah and W. Pugh, “Evaluating static analysis defect warnings on production software,” in Proc. Workshop Program Anal. Softw. Tools Eng. (PASTE), ACM, 2007.
[15] T. Zimmermann, P. Weißgerber, S. Diehl, and A. Zeller, “Mining version histories to guide software changes,” in Proc. 26th Int. Conf. Softw. Eng. (ICSE), IEEE, pp.563–572, 2004.
[16] M. N. Uddin et al., “Software defect prediction employing BiLSTM and BERT-based semantic feature,” Soft Comput., Vol.26, pp.7877–7891, 2022.
[17] S. Jiang, Y. Chen, Z. He, Y. Shang, and L. Ma, “Cross-project defect prediction via semantic and syntactic encoding,” Empir. Softw. Eng., Vol.29, No.80, 2024.
[18] D. Guo et al., “GraphCodeBERT: Pre-training code representations with data flow,” arXiv preprint, 2020.
[19] C. Wang et al., “Sanitizing large language models in bug detection with data-flow,” in Findings Assoc. Comput. Linguistics: EMNLP, pp.3790–3805, 2024.
[20] X. Meng et al., “An empirical study on LLM-based agents for automated bug fixing,” arXiv preprint, 2024.
[21] S. Kim, S. Shivaji, and J. Whitehead, “A reflection on change classification in the era of large language models,” IEEE Trans. Softw. Eng., Vol.51, No.3, pp.864–869, 2025.
[22] D. Ramos et al., “Are large language models memorizing bug benchmarks?” arXiv preprint, 2024.
[23] M. N. Rafi, A. R. Chen, T. Chen, and S. Wang, “Revisiting Defects4J for fault localization in diverse development scenarios,” in Proc. Mining Softw. Repositories Conf. (MSR), ACM, 2025.
[24] R. Just, D. Jalali, and M. D. Ernst, “Defects4J: A database of existing faults to enable controlled studies,” in Proc. Int. Symp. Softw. Test. Anal. (ISSTA), ACM, 2014.
[25] V. Lenarduzzi, F. Lomio, H. Huttunen, and D. Taibi, “Are SonarQube rules inducing bugs?” in Proc. IEEE Int. Conf. Softw. Anal., EVol.Reeng. (SANER), pp.501–511, 2020.
[26] O. Constant, W. Monin, and S. Graf, “A model transformation tool for performance simulation of complex UML models,” in Companion 30th Int. Conf. Softw. Eng., ACM, pp.923–924, 2008.
[27] N. S. Thomas and S. Kaliraj, “An improved and optimized random forest-based approach to predict software faults,” SN Comput. Sci., Vol.5, No.5, p. 530, 2024.
[28] M. Tufano et al., “An empirical study on learning bug-fixing patches in the wild via neural machine translation,” ACM Trans. Softw. Eng. Methodol., Vol.28, No.4, pp.1–79, 2019.
[29] M. N. I. Opu, S. Wang, and S. Chowdhury, “LLM-based detection of tangled code changes for higher-quality method-level bug datasets,” arXiv preprint, 2025.
[30] A. Bilal, D. Ebert, and B. Lin, “LLMs for explainable AI: A comprehensive survey,” arXiv preprint, 2025.
[31] S. Seo et al., “A sentence-level visualization of attention in large language models,” in Proc. NAACL (System Demonstrations), Assoc. Comput. Linguistics, pp.313–320, 2025.
[32] F. Kares, T. Speith, H. Zhang, and M. Langer, “What makes for a good saliency map? Evaluating strategies in explainable AI,” arXiv preprint, 2025.
[33] N. Honest, “Role of testing in software development life cycle,” Int. J. Comput. Sci. Eng., Vol.7, No.5, pp.886–889, 2019.
[34] N. Mishra, “Exploring the impact of Chat-GPT on India’s education system,” Int. J. Comput. Sci. Eng., Vol.11, No.1, pp.1–6, 2023.
Downloads
Published
How to Cite
Issue
Section
License

This work is licensed under a Creative Commons Attribution 4.0 International License.
Authors contributing to this journal agree to publish their articles under the Creative Commons Attribution 4.0 International License, allowing third parties to share their work (copy, distribute, transmit) and to adapt it, under the condition that the authors are given credit and that in the event of reuse or distribution, the terms of this license are made clear.

