
Evaluating the Impact of Audio Segment Duration on Transformer-Based Stuttering Detection Using Wav2Vec2
DOI:
https://doi.org/10.26438/ijcse/v13i7.5157Keywords:
Stuttering detection, Speech processingAbstract
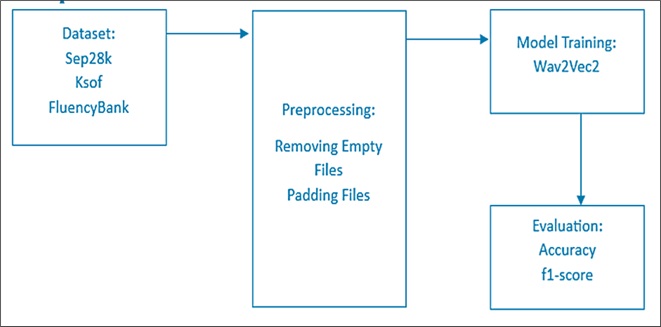
Stuttering is a speech disorder that disrupts the fluency of verbal communication. Traditional assessment methods are subjective and labor-intensive, prompting the need for scalable, automated solutions. Recent advances in self-supervised learning and transformer-based models such as Wav2Vec2 offer promising capabilities for automated stuttering detection. This study investigates the effect of varying audio clip lengths on the classification accuracy of stuttering using Wav2Vec2 models. Experiments were conducted on three benchmark datasets—SEP-28k, FluencyBank, and KSoF—across clip durations ranging from 3 to 11 seconds. Results show that shorter audio segments (3–5 seconds) consistently achieve better classification accuracy, with a peak of 65.13% observed for 3-second segments using SEP-28k. Longer durations introduce performance variability, especially in cross-dataset evaluations. The findings support the design of efficient, real-time stuttering detection systems and inform optimal segment length for future speech analysis models.
References
[1] Shakeel A. Sheikh, Md Sahidullah, F. Hirsch, and S. Ouni, “Machine learning for stuttering identification: Review, challenges and future directions”, Neurocomputing, Vol.514, pp.385-402, 2022. doi: 10.1016/j.neucom.2022.10.015.
[2] V. Changawala and F. Rudzicz, “Whister: Using Whisper’s representations for Stuttering detection”, in Proc. Interspeech 2024.
[3] S. A. Sheikh, M. Sahidullah, F. Hirsch, and S. Ouni, “End-to-End and Self-Supervised Learning for ComParE 2022 Stuttering Sub-Challenge”, arXiv preprint, arXiv:2207.10817, 2022. doi: 10.48550/arXiv.2207.10817
[4] S. P. Bayerl, D. Wagner, E. Nöth, and K. Riedhammer, “Self-supervised learning for stuttering detection: Challenges and opportunities”, arXiv preprint, arXiv:2204.03417, 2022. doi: 10.48550/arXiv.2204.03417.
[5] S. A. Sheikh, M. Sahidullah, F. Hirsch, and S. Ouni, “Advances in Stuttering Detection: Exploring Self-Supervised and End-to-End Learning Approaches”, arXiv preprint, arXiv:2204.01564, 2022. doi: 10.48550/arXiv.2204.01564
[6] S. A. Sheikh, M. Sahidullah, F. Hirsch, and S. Ouni, “Robust Stuttering Detection via Multi-task and Adversarial Learning”, arXiv preprint, arXiv:2204.01735, 2022. doi: 10.48550/arXiv.2204.01735.
[7] R. Alnashwan, N. Alhakbani, A. Al-Nafjan, A. Almudhi, and W. Al-Nuwaiser, “Computational Intelligence-Based Stuttering Detection: A Systematic Review”, Diagnostics, Vol.13, No.23, pp.35-37, 2023. doi: 10.3390/diagnostics13233537.
[8] C. Lea, V. Mitra, A. Joshi, S. Kajarekar and J. P. Bigham, “SEP-28k: A Dataset for Stuttering Event Detection from Podcasts with People Who Stutter”, ICASSP 2021 - 2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, pp.6798-6802, 2021. doi: 10.1109/ICASSP39728.2021.9413520
[9] P. Filipowicz and B. Kostek, “Rediscovering Automatic Detection of Stuttering and Its Subclasses through Machine Learning—The Impact of Changing Deep Model Architecture and Amount of Data in the Training Set”, Applied Sciences, Vol.13, No.10, pp.6192, 2023. doi: 10.3390/app13106192.
[10] Basak, K.; Mishra, N.; Chang, H.-T. TranStutter: A Convolution-Free Transformer-Based Deep Learning Method to Classify Stuttered Speech Using 2D Mel-Spectrogram Visualization and Attention-Based Feature Representation. Sensors, 23, 8033, 2023. doi.org/10.3390/s23198033
[11] A. B. Nassif, I. Shahin, I. Attili, M. Azzeh and K. Shaalan, “Speech Recognition Using Deep Neural Networks: A Systematic Review”, in IEEE Access, Vol.7, pp.19143-19165, 2019. doi: 10.1109/ACCESS.2019.2896880.
[12] T. Kourkounakis, A. Hajavi, and A. Etemad, “Detecting Multiple Speech Disfluencies Using a Deep Residual Network with Bidirectional Long Short-Term Memory”, arXiv preprint, arXiv:1910.12590, 2019. doi: 10.48550/arXiv.1910.12590
[13] T. Kourkounakis, A. Hajavi, and A. Etemad, “FluentNet: End-to-End Detection of Stuttered Speech Disfluencies With Deep Learning”, arXiv preprint, arXiv:2009.11394, 2020. doi: 10.48550/arXiv.2009.11394
[14] S. Khara, S. Singh and D. Vir, “A Comparative Study of the Techniques for Feature Extraction and Classification in Stuttering”, 2018 Second International Conference on Inventive Communication and Computational Technologies (ICICCT), Coimbatore, India, pp.887-893, 2018. doi: 10.1109/ICICCT.2018.8473099
[15] S. A. Sheikh, M. Sahidullah, F. Hirsch, and S. Ouni, “StutterNet: Stuttering Detection Using Time Delay Neural Network”, arXiv preprint, arXiv:2105.05599, 2021. doi: 10.48550/arXiv.2105.05599
[16] Jouaiti, Melanie & Dautenhahn, Kerstin. Dysfluency Classification in Stuttered Speech Using Deep Learning for Real-Time Applications, 2022. 10.1109/ICASSP43922.2022.9746638.
[17] S. P. Bayerl, A. Wolff von Gudenberg, F. Hönig, E. Noeth, and K. Riedhammer”,KSoF: The Kassel State of Fluency Dataset – A Therapy Centered Dataset of Stuttering”, in Proceedings of the Language Resources and Evaluation Conference, Marseille, France: European Language Resources Association, pp.1780–1787, 2022.
[18] K. Floridi and M. Chiriatti, “GPT-3: Its Nature, Scope, Limits, and Consequences”, arXiv preprint arXiv:2006.11477, Sep. 2020. doi.org/10.48550/arXiv.2006.11477
Downloads
Published
How to Cite
Issue
Section
License

This work is licensed under a Creative Commons Attribution 4.0 International License.
Authors contributing to this journal agree to publish their articles under the Creative Commons Attribution 4.0 International License, allowing third parties to share their work (copy, distribute, transmit) and to adapt it, under the condition that the authors are given credit and that in the event of reuse or distribution, the terms of this license are made clear.

