
AI Diffusion: An Android Application for Text-to-Image Generation Using Generative AI Models
DOI:
https://doi.org/10.26438/ijcse/v13i4.3440Keywords:
Text-to-Image Generation, Generative AI, Android Applicatio, , FastAP, Latent Diffusion Model, , Mobile AI, AI-Powered Creativity,, Prompt-Based GenerationAbstract
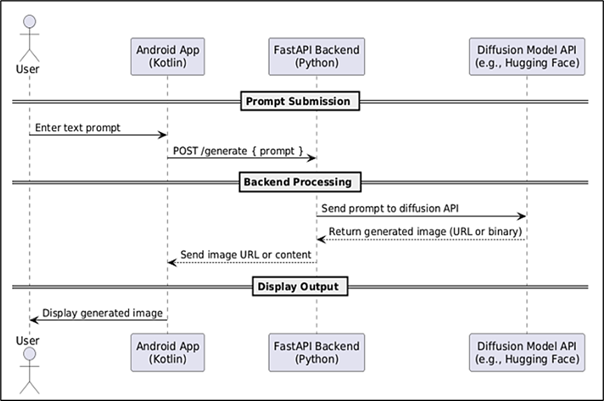
AI Diffusion is an Android-supported text-to-image synthesis application fusing cutting-edge generative artificial intelligence and the pervasiveness of Android platforms. The vision is to provide users with a simple yet incredibly powerful tool with which they can produce realistic and imaginative images from text-based descriptions. Application architecture features an Android frontend developed with Kotlin and Python-based backend authored in FastAPI. Upon entering a prompt by a user, the backend interacts with a pre-trained generative AI model hosted via API to create an associated image, which is then rendered inside the app. The system is optimized to be lean and responsive to support real-time interaction even on resource-constrained devices. Comprehensive testing shows that the app works seamlessly with minimal latency and creates contextually accurate images for all types of prompts. The project bridged the distance between powerful AI functionality and genuine mobile usability, bringing more individuals access to creative tools and enabling them to access them with more ease. The project also enables future upgrade prospects, such as customization options and offline model suitability, to add more feasibility to mobile AI solutions.
References
[1] P. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer, “High-Resolution Image Synthesis with Latent Diffusion Models,” IEEE Transactions on Pattern Analysis and Machine Intelligence, Vol.45, No.7, pp.7985-7999, 2022. https://doi.org/10.1109/TPAMI.2022.3202325
[2] A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, and I. Sutskever, “Learning Transferable Visual Models from Natural Language Supervision,” International Journal of Computer Vision, Vol.130, No.5, pp.1102–1120, 2022. https://doi.org/10.1007/s11263-021-01477-2
[3] A. Ramesh, M. Pavlov, G. Goh, S. Gray, C. Voss, A. Radford, M. Chen, and I. Sutskever, “Zero-Shot Text-to-Image Generation,” In Proceedings of the 38th International Conference on Machine Learning (ICML), PMLR, Vol.139, pp.8821–8831, 2021.
[4] S. L. Mewada, “A Proposed New Approach for Cloud Environment using Cryptic Techniques,” In the Proceedings of the 2022 International Conference on Physical Sciences, ISROSET, India, pp.542–545, 2022.
[5] A. Dadhich, H. Khandelwal, H. Jhalani, and A. Mangal, “Virtual Gesture Fusion (VGF): A Comprehensive Review of Human–Computer Interaction through Voice Assistants and Gesture Recognition,” International Journal of Novel Research and Development (IJNRD), Vol.9, No.4, pp.123–129, 2024.
[6] K. Reddy, S. Janjirala, and K. B. Prakash, “Gesture Controlled Virtual Mouse with the Support of Voice Assistant,” International Journal for Research in Applied Science and Engineering Technology (IJRASET), Vol.10, No.6, pp.2314–2320, 2022.
[7] L. S. Sowndarya, K. Swethamalya, A. Raghuwanshi, R. Feruza, and G. Sathish Kumar, “Hand Gesture and Voice Assistants,” E3S Web of Conferences, Vol.399, pp.04050, 2023. https://doi.org/10.1051/e3sconf/202339904050
[8] Y. Zhang and Y. Li, “Machine Learning in Gesture Recognition: A Comprehensive Survey,” ACM Computing Surveys, Vol.54, No.5, pp.1–37, 2021. https://doi.org/10.1145/3446370
[9] C. Chen and C. Wang, “Gesture Recognition in Human-Computer Interaction,” Journal of Ambient Intelligence and Humanized Computing, Vol.11, No.3, pp.1013–1026, 2020. https://doi.org/10.1007/s12652-019-01382-3
[10] E. O`Neill and A. O`Brien, “Voice Devices and User Experience: Understanding Design Trade-offs,” International Journal of Human-Computer Studies, Vol.127, pp.1–12, 2019. https://doi.org/10.1016/j.ijhcs.2018.12.001
Downloads
Published
How to Cite
Issue
Section
License

This work is licensed under a Creative Commons Attribution 4.0 International License.
Authors contributing to this journal agree to publish their articles under the Creative Commons Attribution 4.0 International License, allowing third parties to share their work (copy, distribute, transmit) and to adapt it, under the condition that the authors are given credit and that in the event of reuse or distribution, the terms of this license are made clear.

